Im Rahmen meiner Trainer-Tätigkeit kommen in den Kursen immer wieder Fragestellungen zu Themen die im Kurs nur am Rande oder gar nicht abgehandelt werden. Diese Artikelserie gibt angehenden IT-Experten Hilfsmittel für den täglichen Gebrauch an die Hand.
Intro – Was sind Diskgruppen?
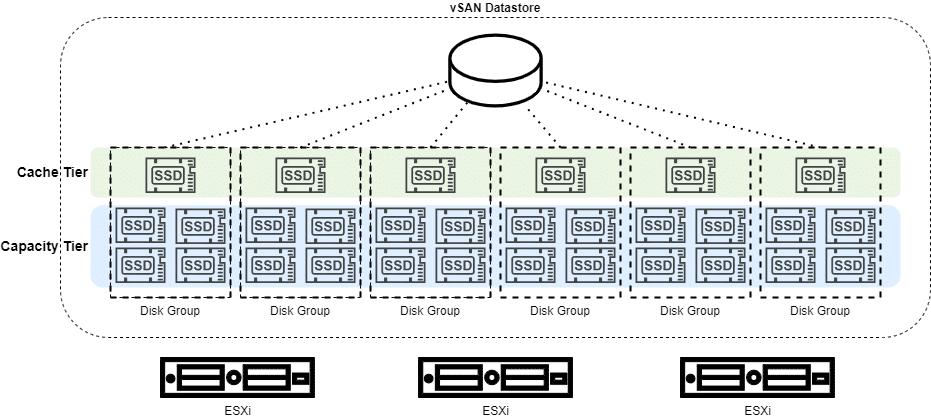
VMware vSAN OSA (original storage architecture) organisiert den vSAN-Datenspeicher in Diskgruppen (DG). Jeder vSAN-Knoten kann bis zu 5 Diskgruppen enthalten. Jede dieser Diskgruppen besteht aus genau einem Cache-Device (SSD) und mindestens einem bis maximal 7 Capacity-Devices pro Gruppe. Diese dürfen entweder magnetische Disks oder SSD sein, jedoch keine Mischung aus beiden. Wir unterscheiden in Cache-Tier und Capacity-Tier.
Die Verwaltung der Diskgruppen kann anschaulich über das graphische Userinterface GUI erfolgen. Es gibt jedoch Situationen in den das Diskgruppen Managemenent auf der CLI notwendig oder zweckmäßiger ist.
UUID
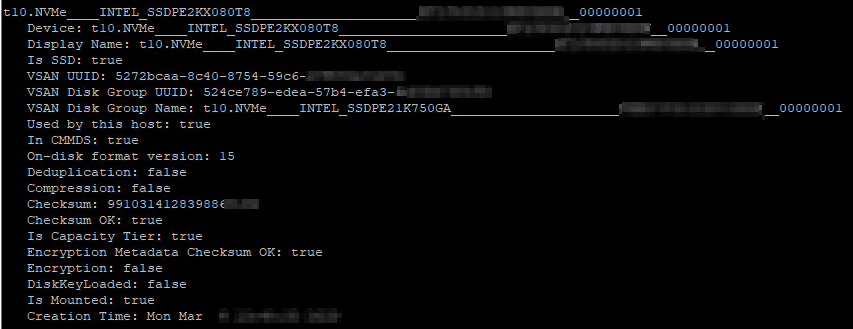
Jedes Disk Device eines vSAN Clusters (OSA) hat eine eindeutige und einzigartige Kennung (universal unique identifier, UUID).
Wir können alle Devices eines vSAN Knotens auf der CLI auflisten mit dem Kommando:
esxcli vsan storage list
Die Menge an Information ist möglicherweise etwas zu viel des Guten und wir möchten nur die Zeilen mit UUID anzeigen lassen.
esxcli vsan storage list | grep UUID
Wir erhalten eine Liste aller Disk-Devices im vSAN-Knoten. Zusätzlich erhalten wir auch die UUID der Diskgruppe, welcher das Device zugeordnet ist.
Schaut man sich die Ausgabe etwas genauer an, so fällt auf dass es einige Devices gibt, deren UUID identisch mit der UUID der Diskgroup ist. Ist dies ein Widerspruch zur Aussage, die UUID sei einzigartig? Nein. Es handelt sich hier um Cache-Devices. Jede Diskgruppe in vSAN OSA besteht aus genau einem Cache Device. Die Diskgruppe übernimmt hierbei die UUID ihres Cache-Devices. Wir können also auf diese Art schnell ein Cache Device von einem Capacity Device unterscheiden.
„Teach-The-Expert: vSAN Diskgruppen Verwaltung auf der CLI“ weiterlesen