Recently I activated Tanzu with NSX-T in my homelab. After some hurdles in the planning phase, the configuration worked fine and also north-south routing worked flawlessly. My edge nodes established BGP peering with the physical router and advertised new routes. New segments are immediately available without further configuratiom on the router.
One feature that distinguishes my lab from a production environment is that it doesn’t run 24/7. After the work is done, the whole cluster is shut down and the system is powered off. An idle cluster makes a lot of noise and consumes unnecessary energy.
Recently I booted the lab and observed that no communication with the router or DNS server was possible from my NSX segments. A perfect case for troubleshooting.
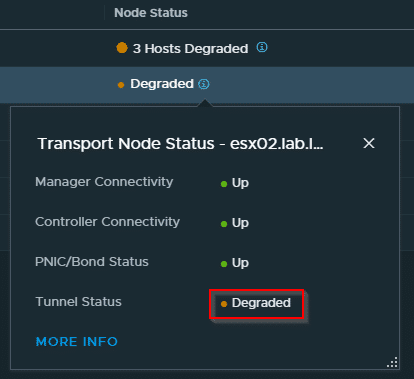
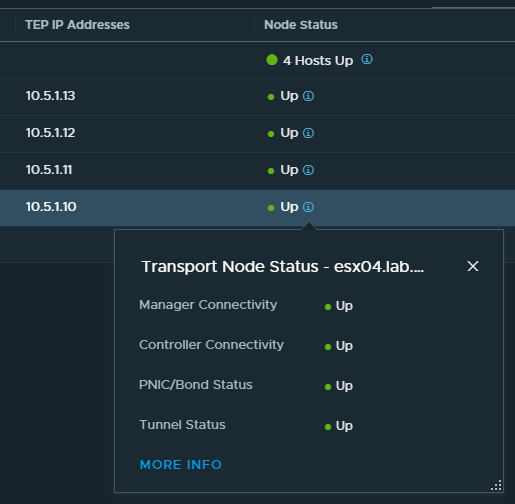
First I checked the Geneve tunnels between the transport nodes. Here everything was fine and every transport node was able to communicate with every other transport node. The root cause was quickly located in the edge nodes. Neither a reboot of the edges nor a vMotion to another host did improve the situation.
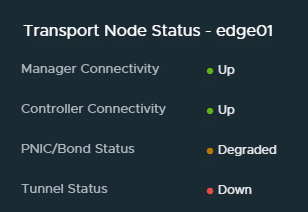
The Edges weren’t completely offline. They were administrable using the management network. Traceroute was working via T1 and T0 service routers up to the fastpath interface fp-eth0. From there, no packets were forwarded.
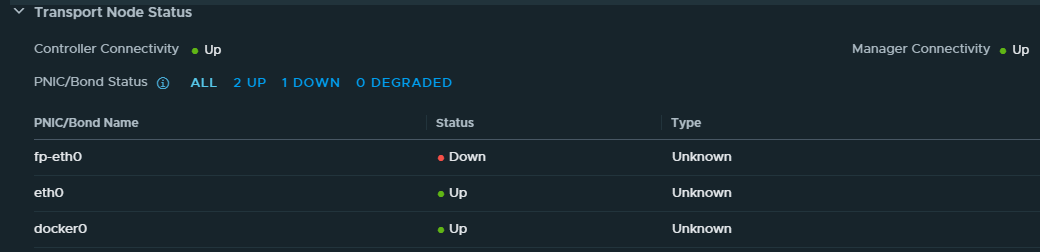
The interface fp-eth0 is connected to the distributed port group “Edge-Trunk” on vSwitch VDS-NSX. A quick check in the vSphere client showed that the uplink ports of both edges were blocked. Not in the “down” state, but blocked.

At this point, I would ask a customer what he has changed. But I am very sure that I did not make any changes to the system or the configuration. Yes, they all say that 😉
Scotty, unblock me!
After some searching, I was fortunate to find a VMware KB article describing the phenomenon. The explanation of the cause did not precisely fit my scenario, but the instructions for unlocking were effective. There is a second KB article 66796 that is more applicable, though only for NSX-T versions prior to 2.4.1, which I do not use.
First step is to open a SSH connection to a transport node (esx01), where one of the edge-node VMs is registered.
[root@esx01:~] net-dvs -l | grep -E "port |port.block|volatile.vlan|volatile.status"
The output can be a longer list depending on the environment. The following excerpt and screenshot shows the important section.
port 49fe0adb-2ab4-471b-9b81-12119b46f7f2:
com.vmware.common.port.volatile.status = inUse linkUp blocked portID=100663332 Port blocked by admin propType = RUNTIME

In the next step we have to match the port number 100663332. Unfortunately, the naming is not always consistent here. In the output the port number is called PortID, but in the next query it is called PortNum. The PortUUID 49fe0adb-2ab4-471b-9b81-12119b46f7f2 was given in the first output, but we will determine it again later.
[root@esx01:~] net-stats -l
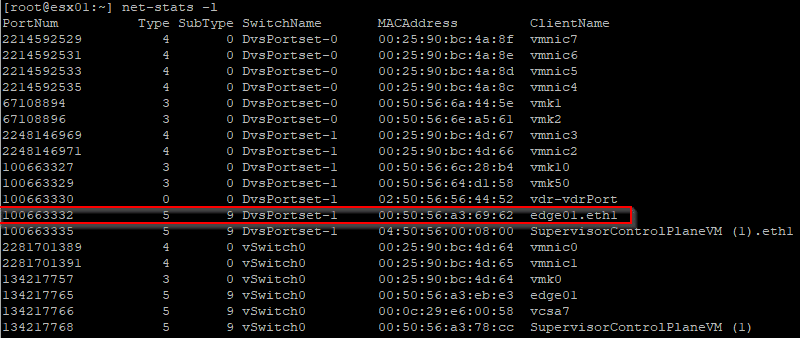
The port number 100663332 matches the blocked port eth1 of the VM edge01 (internal name: fp-eth0). If the VDS with the port group is not known, it can be queried with the following command. This way we also determine the PortUUID, which is referred to as DVPort ID here.
[root@esx01:~] esxcfg-vswitch -l
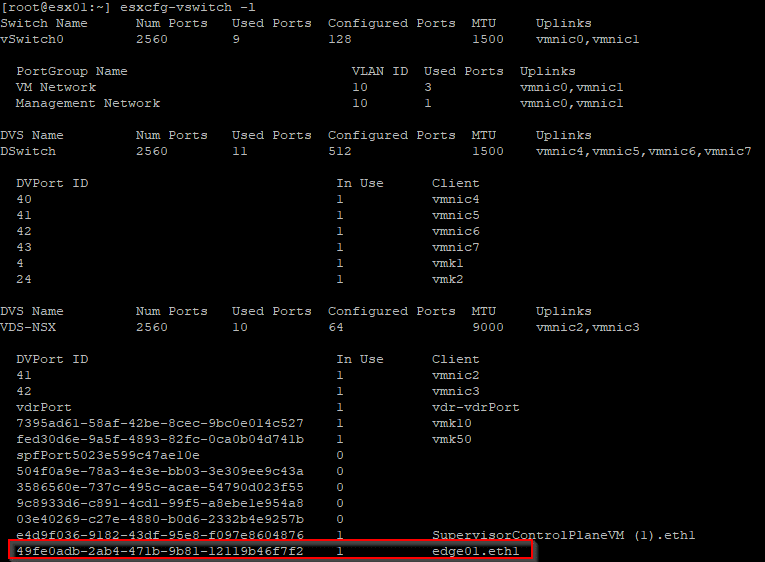
The DVS name is VDS-NSX and the PortUUID is 49fe0adb-2ab4-471b-9b81-12119b46f7f2, so we have the necessary information to unlock the ports. The general command is:
net-dvs -s com.vmware.common.port.block=false <VDS-Name> -p <PortUUID>
net-dvs -s com.vmware.common.port.block=false VDS-NSX -p 49fe0adb-2ab4-471b-9b81-12119b46f7f2
You can instantly check the result in vSphere-Client. Sometimes a refresh is needed.
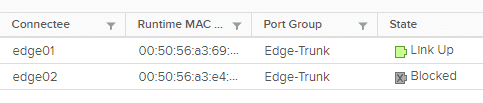
In NSX-T manger the state of port fp-eth0 is “up” too.
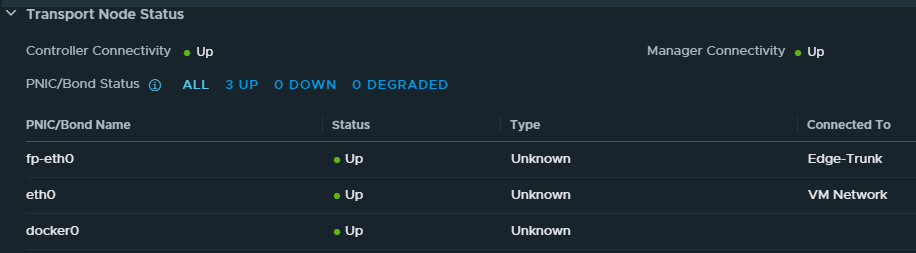
The above procedure was repeated for VM edge02. After that, its port in the vSphere Client was brought back online as well.

In the NSX-T manager, the situation had not recovered immediately. Only after a vMotion of the edge VMs all indicators went green there. Possibly I was also a bit too impatient.
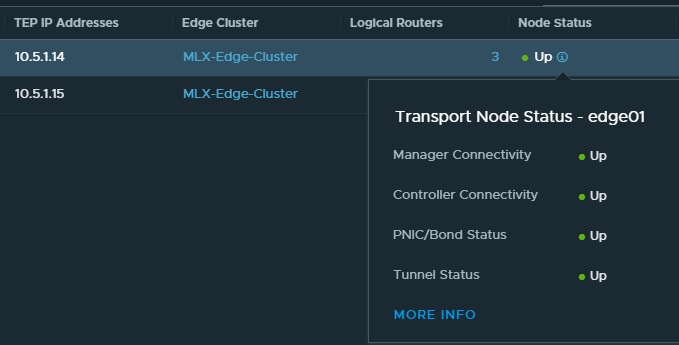
The four transport nodes are also completely in “green” state again.