
Snapshot-Only-Jobs
Snapshots != Backups
When talking about storage integration into Veeam most of the people think of BfSS only. As we have seen, this is a great feature to lower the impact your current backup jobs have on your production environment.
An often-overlooked feature of the storage integration with Veeam is a totally new concept that can be leveraged in addition: Snapshots on the storage system can be used for recoveries directly – without having to backup the data to a Veeam repository first.
The Veeam storage plugin for DataCore allows for a recovery of full VMs via Instant-Recovery as well as a recovery of guest files or even application items like emails or SharePoint items.
A storage snapshot should by no means be considered a backup. This is in contrast to what some (not DataCore though) storage vendors try to teach their customers. That is to rely on only a cascade of snapshots and copies of those snapshots to other physical boxes of the same vendor in other fire zones. As long as the backed-up data never leaves the little universe the proprietary storage firmware summons, I would never allow a backup strategy to rely on only those storage volume snapshots.
Size matters…minimize your RPO!
Though those snapshots can nicely complement your backup strategy as they can be created in the blink of an eye. Depending on the storage system we can hold a certain amount of those snapshots concurrently without impacting the performance of the storage array too negatively. For DataCore this shouldn’t be too much right now. I wouldn’t go up to 200+ snapshots with a productive DataCore cluster right now. But a wisely sized DataCore cluster should be capable to hold e.g. one snapshot created at each full hour throughout the working day. During the backup windows at night we would still generate a “real” backup through Veeam – maybe using BfSS – but onto a repository being fully independent from your primary storage system.

With this concept maybe 12 concurrent snapshots could be enough to hold an extra recovery at every full hour between e.g. 8am and 8pm, when the full backup are created. Thus, we would gain a much lower RPO than before (1h during the office hours compared to up to 24h with only a nightly backup).
Watch for your performance and your free space when snapping DataCore LUNs
As always, test it with your individual DataCore cluster. Look for performance issues for your production workloads when having those snapshots open. The copy-on-first-write has an impact on your storage IO.
Also make sure to cope for the additional amount of data you will need for storing the snapshot data (reverse deltas, as we do a copy-on-first-write, see above). I would recommend to have an independent disk pool in DataCore ready to be used as your snapshot pool. This is where all the deltas and the snapshot metadata go. Per default DataCore puts all that into the same disk pool. Thus, you can direct snapshot related IO as well as extra volume consumption to an independent disk array.
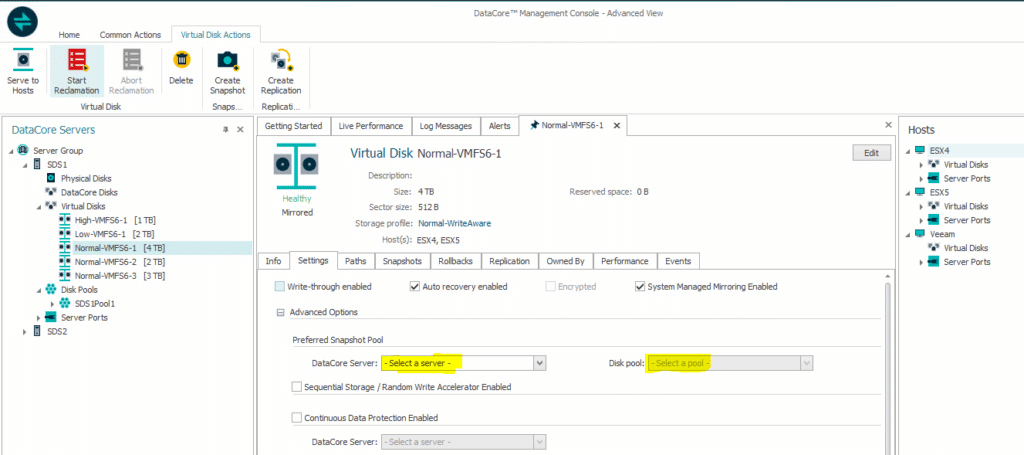
Many ways to Rome … three to LUN snapshots
We have at least three ways of creating those volume snapshots in your DataCore cluster to be able to consume them from inside Veeam:
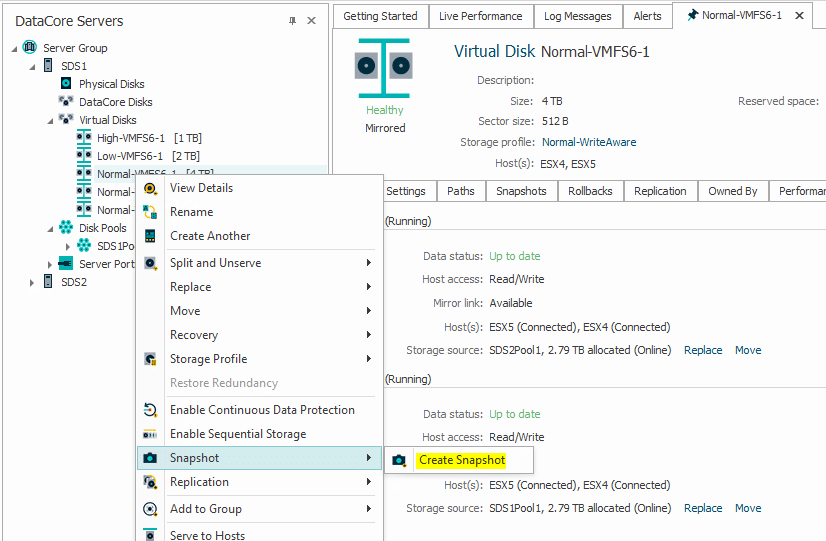
1. Create the snapshot manually or scripted inside DataCore, independent from Veeam, but still be able to use them from within VBR.
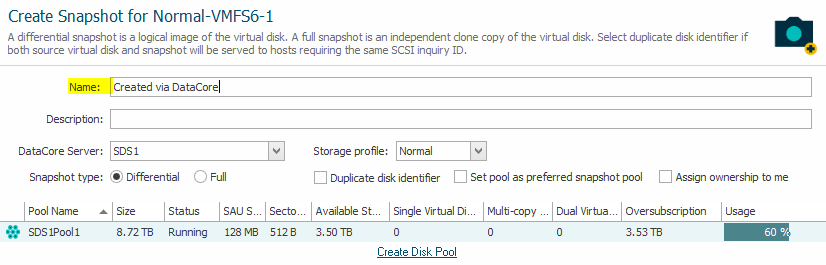
The name can be changed as I did in the example and will be visible inside the Veeam console as well. Keep to the “Differential” type that consumes much less space as a full snapshot – that would be a clone of the volume – and also leave the other options at their defaults. Veeam can handle a different identifier for the snapshot volume.
2. Create the snapshot manually inside VBR through the “Storage Integration” menu.
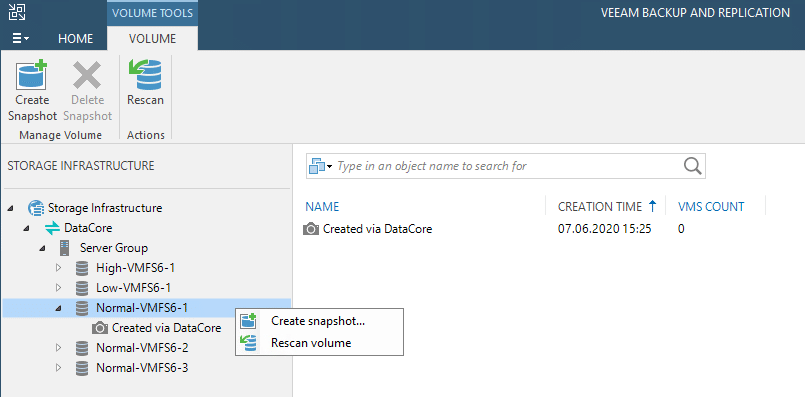
Here also an explanatory name can be applied.
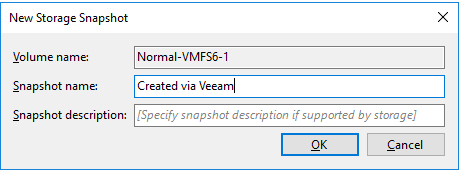
The snapshot and its name will be steered to DataCore through the storage API. Meanwhile you can follow the process in a process window.
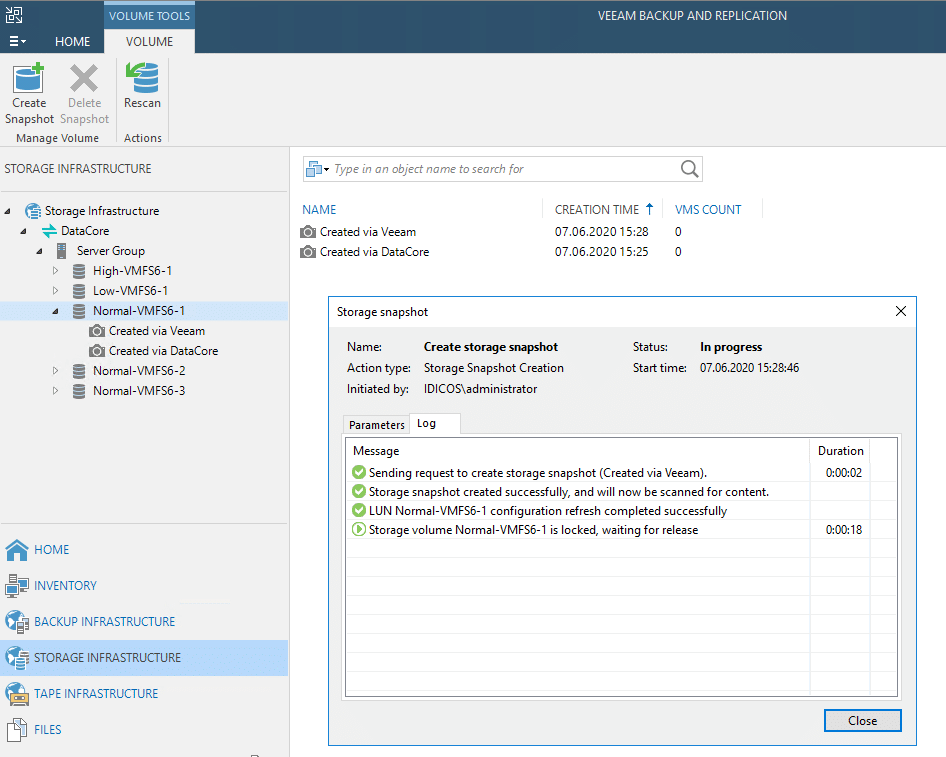
Method 1 and 2 lead to the exact same result. A snapshot on a DataCore LUN, being reflected with the same name in the Veeam GUI. After having been scanned by Veeam the console will show all the VMs that the snapped LUN carries. All VMs will be shown as “crash-consistent” as no application integration has been involved. On the other hand, all VMs will by contained at the exact same point-in-time. Something one could never achieve with application consistent snapshots as they are generated via independent VMWARE snapshots.
3. Create the snapshot automatically through a backup job that insted of pointing to a repository has “DataCore Snapshot” set as its repository.
Just point a regular backup job to “DataCore Snapshot” as its repository and add VMs or containers for VMs as usual.
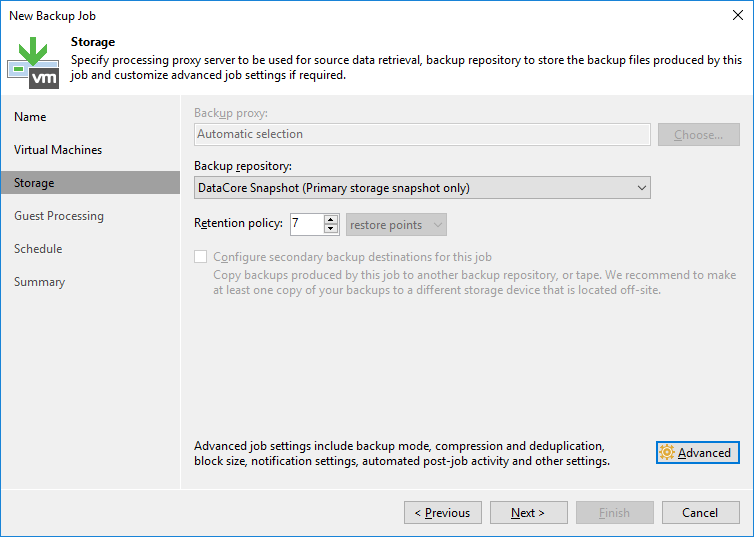
The retention policy reflects the total number of snapshots which we will hold concurrently, before the oldest one will be deleted. To follow our example from above, we would have to set it to 12.
With this method we even can, in contrast to the two options above, trigger the famous application integration processes to gain application consistency for your workloads.
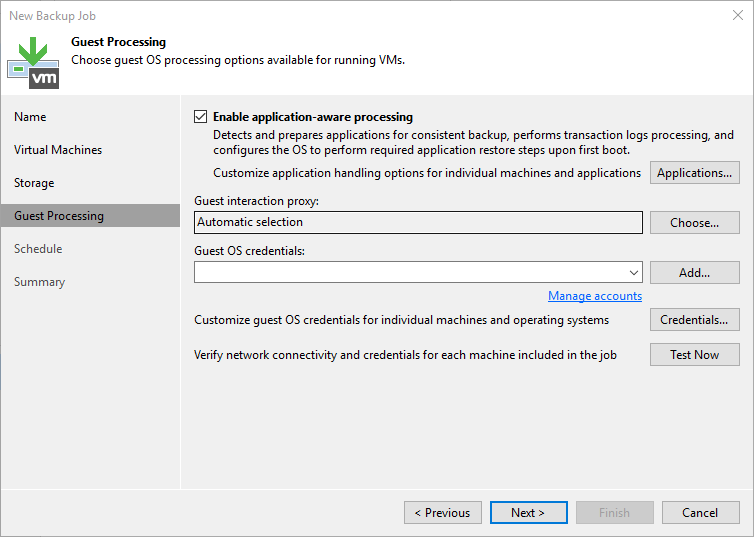
Keep in mind that application integration always takes extra time as it needs a VMWARE snapshot as well. Thus, for the low-RPO snapshots throughout the day we could go for crash-consistent snapshots only. We will still be able to recover data from them. There is though a risk of inconsistencies. We could combine both and have e.g. a single application consistent one at noon and keep the rest fast and only crash-consistent.

Using the schedule shown, you would generate the above mentioned one snapshot per hour between 8am and 8pm on working days.
LUN Snapshots are scanned for VMs
Snapshots are always created almost immediately, but before we can restore data from them, they have to be scanned by Veeam for VMs. With the current Veeam plugin for DataCore this scan sometimes takes a while. In my environment it takes up to 15 minutes, before the contents of the snapshot are shown. Especially when you trigger concurrent snapshot processes from inside VBR at the same time.
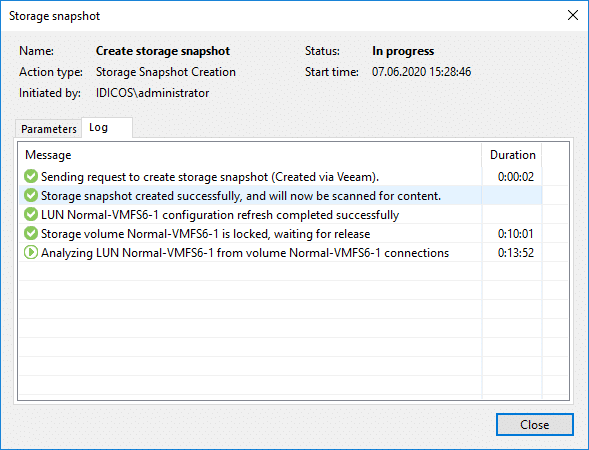
Once the scan is finished, the VMs will show up in Veeam and offer different ways to recover data from them. We’ll cover that in the next chapter.
Hi All,
Good News on the way, Datacore PSP14 will come soon and will give new features through CDP. Thanks to this update Veeam will be able to directly access the Datacore CDP. No more need Datacore Snapshot. Big Data economy and big flexybility.
Veeam normaly will update VBR just after and thats’it. We’ll all be able to recover a VM or guest files from reading Datacore CDP in point in time. (depending on how much you allocated to DC CDP for sure)
Hi Loïc.
Thanks for the update. To my knowledge it will even be uncoupled from PSP14 and is to be released as an updated plugin pretty soon.
An update to the blog post will follow. In general it will deliver the same outcome but the process will be much easier to handle.
Great news for DataCore users having a slight fear of ransomware (who does not?). 😉
Hi All,
which SAU size would you recommend for the snapshot pool?
If you use CDP, is there any advisory which SAU size should be used?
I read the Veeam digest from gostev. Veeam released the CDP feature in their updated Datacore plugin. I’m really looking forward to your blog post update.
Hi Alfred.
For a pure snapshot pool one might want to go as small as possible. I usually stick with 8 MB. 4 MB could also be an option. The smaller, the longer the pool can support your snapshots.
For CDP I did not find a best-practice recommendation. Through talks to DataCore SEs I narrowed my personal best-practice to 32MB as a trade off between overhead and granularity.