
What is beacon probing?
In my recent blog article “ESX physical uplink resiliency” I’ve discussed countermeasures to harden vSphere traffic against downstream physical failures. Today I will discuss another failover detection method which can handle uplinks that are not yet dead but not functional either.
Reasons for failure can be driver / firmware related errors on the NIC itself, or a broken downstream path (cable / switch).
Beacon probing
Beacon probing is a mechanism, where an ESX host will send out beacon packets over every uplink port every second to verify that each other uplink is reachable.
![]()
As long as vmnic0 receives beacons from vmnic1 and vmnic2, the host knows two things:
- vmnic0 is connected and functional
- vmnic1 and vmnic2 are connected and functional
This method has the advantage, that a dead path downstream of a vmnic uplink can be detected. Also a port malfunction can be detected, because it will neither send nor receive beacons. VMs can failover to uplink ports that are functional.
![]()
Here we have a downstream failure between Switch1 and Core. Physical link state of vmnic1 is “up” because there’s an active link to Switch1. In contrast would failover detection mechanism “link state only” report vmnic1 as good. But beacon probing identifies a problem somewhere on the path to/from vmnic1. VMs on portgroup PG1 will fail over to vmnic2.
Pitfalls of beacon probing
This method has some implications to work properly.
Use more than two uplinks
To avoid a split brain scenario, you should at least have 3 uplink ports per vSwitch. If you only have two uplinks, it’s impossible for the host to tell which vmnic is the cause of a problem. There will be no more beacons.
![]()
Connect uplinks to different physical switches
If you connect uplink ports to the same physical switch, it will turn beacon probing more or less useless, because you shunt the beacon connection on Switch0. A potential problem further downstream remains undetected.
![]()
False negatives and false positives
If you connect more than one uplink to the same switch and use beacon probing you can get paradox effects where a functional link path will be treated as failed and broken uplinks as good.
Take a look at the picture below. Switch1 has lost its connection to the Core, but vmnic1 and vmnic2 are still exchanging beacons. On the other hand the path over Switch0 is the only real functional link, but it will not receive beacons from vmnic1 or vmnic2 and therefore treated as failed. Portgroup PG0 will failover to one of both uplinks vmnic1 or vmnic2.
![]()
Communication of the vSwitch with the outside world will stop, although there is still one functional link (Uplink0) left.
What about clustered switch units?
What if we’re connecting our uplinks to switch units that are part of a switch-cluster like IRF?
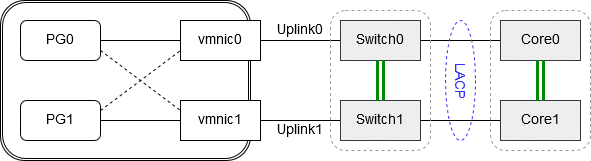
We need to treat uplinks connected to units of a switch-cluster similar to uplinks connected to a single switch. In such cases the recommended failover detection method is “link state only”.
Things you should not do
Take special care with combinations of failover detection methods and load-balancing in vSwitches.
- Do not combine “beacon probing” and load balancing to “Route based on IP Hash” -> See: KB 1017612
- Do not combine beacon probing with etherchannel -> KB 1012819