Mit Einführung von vSphere 7.0 Update 1 erschienen in vSphere-Clustern erstmals die vSphere Cluster Services VMs (vCLS). Damit wurden Cluster Funktionen wie z.B. Distributed Resource Scheduler (DRS) und andere erstmals unabhängig von der Verfügbarkeit der vCenter Server Appliance (VCSA). Letztere stellt im Cluster immer noch einen Single-Point-of-Failure dar. Durch Auslagerung der DRS Funktion in die redundanten vCLS Maschinen wurde ein höheres Maß an Resilienz erreicht.
Retreat Mode
Der vSphere-Administrator hat nur wenig Einfluss auf die Bereitstellung dieser VMs. Gelegentlich ist es jedoch notwendig, diese VMs von einem Datastore zu entfernen wenn dieser beispielsweise in den Wartungsmodus versetzt werden soll. Dafür gibt es eine Prozedur, um den Cluster in den sogenannten Retreat-Mode zu setzen. Dabei werden temporäre erweiterte Einstellungen gesetzt, die zur Löschung der vCLS VMs durch den Cluster führen.
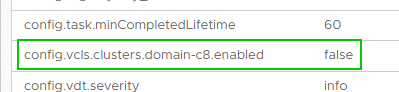
Laut Prozedur von VMware muss für die Aktivierung des Retreat Modes die Domain ID ermittelt werden. Die Domain ID ist der numerische Wert zwischen ‚domain-c‘ und dem folgenden Doppelpunkt. Im Beispiel aus meinem Labor ist es der Wert 8, aber die Zahl kann durchaus auch vierstellig sein.
Die Domain ID muss dann in den Advanced Settings des vCenters übergeben werden.
config.vcls.clusters.domain-c8.enabled = false
Korrekte Settings für den Retreat Mode.
Admin Fehler beim Retreat Mode
Nach Aktivierung des Retreat-Modes auf einem vSAN-Cluster hatten Administratoren sämtliche Privilegien auf alle Objekte im vSphere-Client verloren.
Eine Überprüfung der Dienste zeigte, dass der vCenter Server Daemon (vpxd) nicht gestartet war.
Seit kurzer Zeit bin ich im Besitz eines Maxtang NX6412-B11 Mini PCs. Zur VMware Explore EMEA in Barcelona verteilte Cohesity diese Barebones an vExperts. An dieser Stelle nochmal einen herzlichen Dank an Cohesity für ihren Support der Community!
Der lüfterlose MiniPC mit Elkhart Lake Chipsatz ist gut ausgestattet. Er verfügt über 2x 1 Gbit LAN, 1x USB-C (front), 2x USB 3.2 (front), 2x USB 2.0, 2x HDMI 2.0, sowie einen Audio Port.
Ausstattung der Geräterückseite
Der MiniPC wird mein Homelab bereichern. Ich hatte dafür eine Installation der Tanzu-Community-Edition geplant. Leider wurde das Projekt inzwischen von VMware eingestellt und die Entfernung der Pakete aus GitHub angekündigt. 🙁
Bestückung der Hardware
Der Barebone musste noch mit RAM und einer Flashdisk ausgestattet werden. Ich verbaute eine Samsung SSD 860 EVO Series 1TB M.2 SATA und zwei mal 16 GB SO-DIMM DDR4 3200 von Crucial.
Reboot Probleme unter Linux
Mit der SATA SSD und dem RAM war der PC bereit zum booten. Als System wurde ein Ubuntu 22.04 LTS verwendet. Nach Installation wurde ein Reboot gefordert. Dabei schaltete sich der PC jedoch nicht vollständig ab und blieb im Status „Reached target Shutdown“ stehen. Der PC musste hart abgeschaltet werden. Auch der Neustart dauerte mehrere Minuten, was für Ubuntu sehr ungewöhnlich ist. Um auszuschließen dass das Problem spezifisch für Ubuntu ist, versuchte ich eine Installation mit Fedora. Das Ergebnis war auch hier das gleiche.
Die Lösung
Nach länger Suche fand ich einen Hinweis der spezifisch für die EHL Hardware Plattform war. Die Lösung ist die Deaktivierung eines Kernelmoduls für den Intel Elkhart Lake SoC Chipsatz. Dazu wird dieses in die Blacklist.conf eingetragen.
sudo vi /etc/modprobe.d/blacklist.conf
Folgende Zeile muss in die blacklist.conf eingefügt werden:
blacklist pinctrl_elkhartlake
Den Editor mit [ESC] [:] wq! (save und exit) verlassen.
update-initramfs –u
Der folgende Shutdown war noch verzögert, jedoch startete das Linux nach dem Neustart innerhalb weniger Sekunden.
Ich hoffe dieser Hinweis hilft meinen vExpert Kollegen. Sharing is caring. 🙂
Um einen Einblick in VMware Tanzu und Kunernetes zu erhalten benötigt man keinen Enterprise-Cluster. Dank der Tanzu Community Edition (TCE) kann das jetzt jeder selbst ausprobieren – kostenlos. Der Funktionsumpfang ist nicht beschränkt im Vergleich zu kommerziellen Tanzu Versionen. Lediglich auf professionellen Support durch VMware muss man bei der TCE verzichten. Dieser wird über Foren, Slack-Gruppen oder Github durch die Community geleistet. Für einen PoC Cluster oder zum Training auf die CKA Prüfung reicht das vollkommen aus.
Die Bereitstellung geht recht schnell und man hat nach einigen Minuten einen funktionsfähigen Tanzu-Cluster.
TCE Architektur-Varianten
Die TCE kann in zwei Varianten entweder als Standalone-Cluster oder als Managed-Cluster bereitgestellt werden.
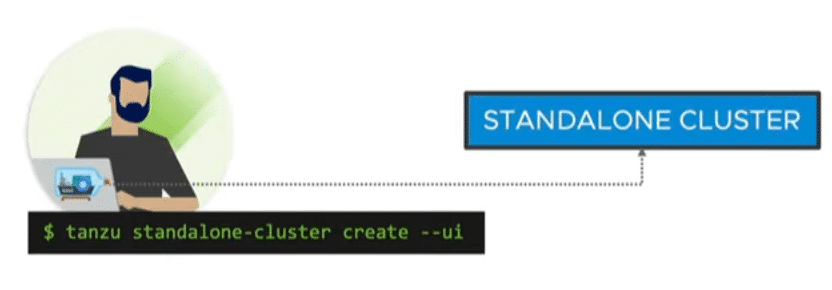
Standalone Cluster
Eine schnelle und Ressourcen schonende Art der Bereitstellung ohne Management-Cluster. Ideal für kleine Tests und Demos. Der Standalone-Cluster bietet kein Lifecycle Management. Dafür hat er einen kleinen Fussabdruck und kann auch in kleinen Umgebungen genutzt werden.
Quelle: VMware
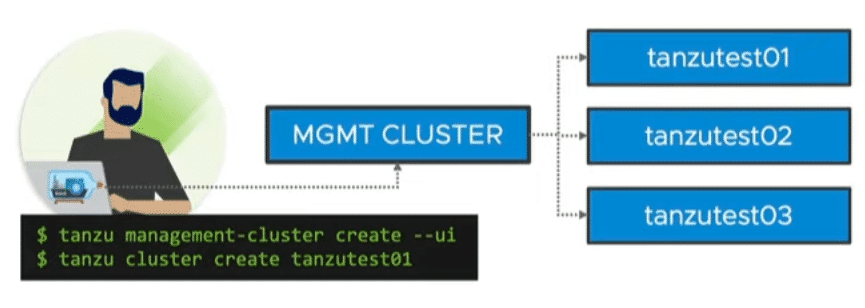
Managed Cluster
Wie bei kommerziellen Tanzu-Versionen gibt es einen Management-Cluster und 1 bis n Workload-Cluster. Er verfügt über Lifecycle Management und Cluster-API. Somit kann über deklarative Konfigurationsdateien der Kubernetes Cluster definiert werden. Beispielsweise die Anzahl der Knoten im Management Cluster, die Anzahl der Worker-Nodes, die Version des Ubuntu-Images oder der Kubernetes Version. Cluster-API stellt die Einhaltung der Deklaration sicher. Fällt beispielsweise ein Worker Node aus, so wir dieser automatisch ersetzt.
Durch die Verwendung mehrerer Knoten benötigt der Managed-Cluster natürlich auch deutlich mehr Ressorcen.
Quelle: VMware
Ziele für die Bereitstellung
TCE kann entweder lokal auf der Workstation mit Docker, im eigenen Lab/Datacenter auf vSphere, oder in der Cloud auf Azure oder aws bereitgestellt werden.
Ich habe im Lab ein lizensiertes Tanzu mit vSAN und NSX-T integration eingerichtet. Daher würde TCE auf vSphere hier keinen tieferen Sinn ergeben. Cloud Ressourcen auf aws oder Azure kosten Geld. Daher möchte ich die kleinstmögliche und sparsamste Bereitstellung eines Standalone-Clusters mit Docker beschreiben. Dazu verwende ich eine VM auf VMware-Workstation. Alternativ kann auch ein VMware-Player oder eine andere Art Hypervisor genutzt werden.
Mit vSphere7 kamen grundlegende Veränderungen im Aufbau des ESXi Bootmediums. Eine starre Partitionsstruktur musste einer flexibleren Partitionierung weichen. Dazu später mehr.
Mit vSphere 7 Update 3 kam auch eine schlechte Nachricht für alle, die USB- oder SDCard-Flashmedien als Bootdevice nutzen. Steigende Lese- und Schreibaktivität führte zu schneller Alterung und Ausfall dieser Medien, da sie für ein solches Lastprofil nie ausgelegt waren. VMware hat diese Medien auf die Rote Liste gesetzt und der vSphere Client wirft Warnmeldungen, sollte ein soches Medium noch verwendet werden. Wir werden uns ansehen, wie man USB- oder SDCard-Bootmedien ersetzen kann.
ESXi Bootmedium: Gestern und heute
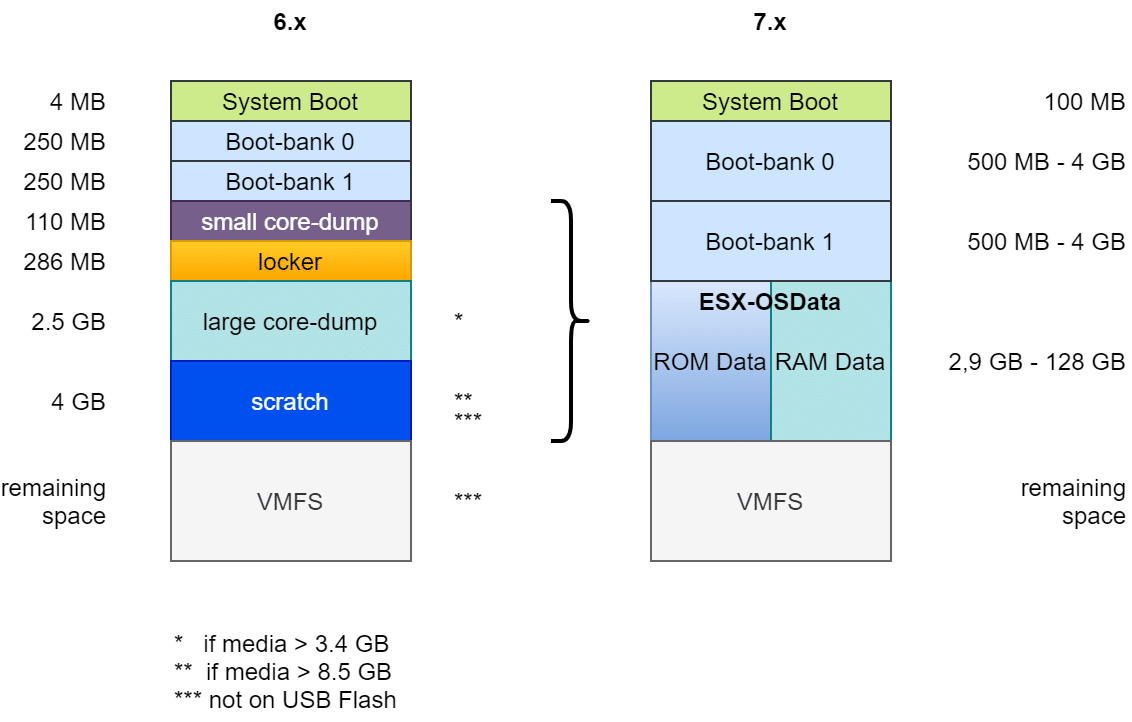
In der Vergangenheit bis Version 6.x war das Bootmedium relativ statisch. War der Bootvorgang erst einmal abgeschlossen, so war das Medium nicht mehr wichtig. Es gab allenfalls eine gelegentliche Leseanfrage einer VM auf das VM-Tools Verzeichnis. Selbst ein Medium, das im laufenden Betrieb kaputt ging, beeinträchtigte den ESXi Host nicht. Problematisch wurde nur ein Neustart. So konnte man beispielsweise auch bei defektem Bootmedium noch die aktuelle ESXi Konfiguration sichern.
Aufbau eines ESXi Bootmediums vor Version 7
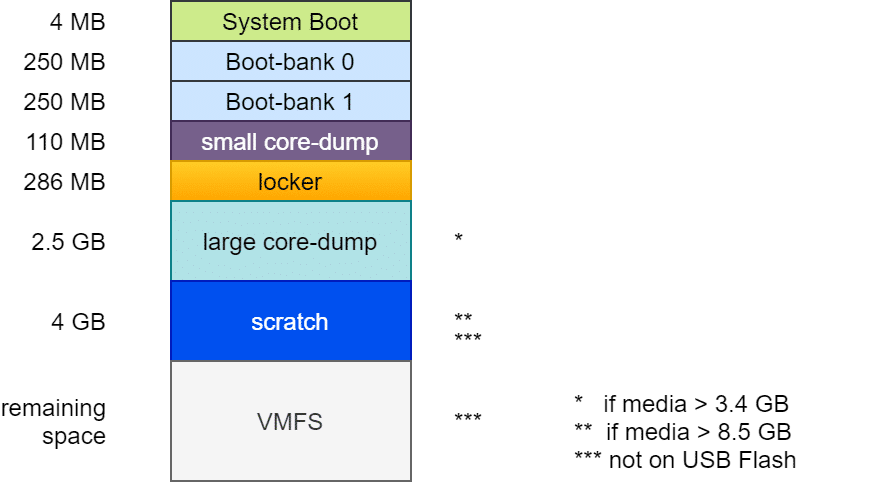
Aufbau des Bootmediums bis ESXi 6.7
Der Aufbau war im Prinzip fast immer gleich: Ein Bootloader von 4 MB Größe (FAT16), gefolgt von zwei Bootbänken mit je 250 MB. Diese enthalten die komprimierten Kernelmodule, die beim Systemstart entpackt und ins RAM geladen werden. Eine zweite Bootbank ermöglicht ein Rollback im Falle eines fehlgeschlagenen Updates. Es folgt eine „Diagnostic Partition“ von 110 MB für kleine Coredumps im Falle eines PSOD. Die Locker oder Store Partition enthält z.B. ISO Images mit VM-Tools für alle unterstützten Gast-OS. Von hier aus werden VM-Tools ins die Gast VM eingebunden. Eine häufige Fehlerquelle bei der Tools Installation war ein beschädigtes oder verlorenes Locker Verzeichnis.
Die folgenden Partitionen unterscheiden sich je nach Größe und Art des Bootmediums. Die zweite Diagnostic-Partition von 2,5 GB wurde nur angelegt, wenn das Bootmedium mindestens 3,4 GB groß ist (4MB + 250MB + 250MB + 110MB + 286MB = 900MB). Zusammen mit den 2,5 GB der zweiten Diagnostic Partition erfordert das 3,4 GB.
Eine 4 GB Scratch Partition wurde nur auf Medien mit mindestens 8,5 GB angelegt. Sie enthält Informationen für den VMware Support. Alles darüber hinaus wurde als VMFS-Datenspeicher bereitgestellt. Scatch und VMFS Partition wurden jedoch nur angelegt, wenn das Medium kein USB-Flash oder SDCard Speicher war. In diesem Fall wurde die Scratchpartition im RAM des Hosts angelegt. Mit der Folge, dass bei einem Host Crash auch alle für den Support wertvollen Informationen verloren gingen.
Aufbau des Bootmedium ab ESXi 7
Das oben skizzierte Layout machte die Verwendung großer Module oder Fremdanbietermodule schwierig. Folglich musste das Design des Bootmedium grundlegend verändert werden.
Veränderung des Partitionslayouts zwischen Version 6.x und 7.x
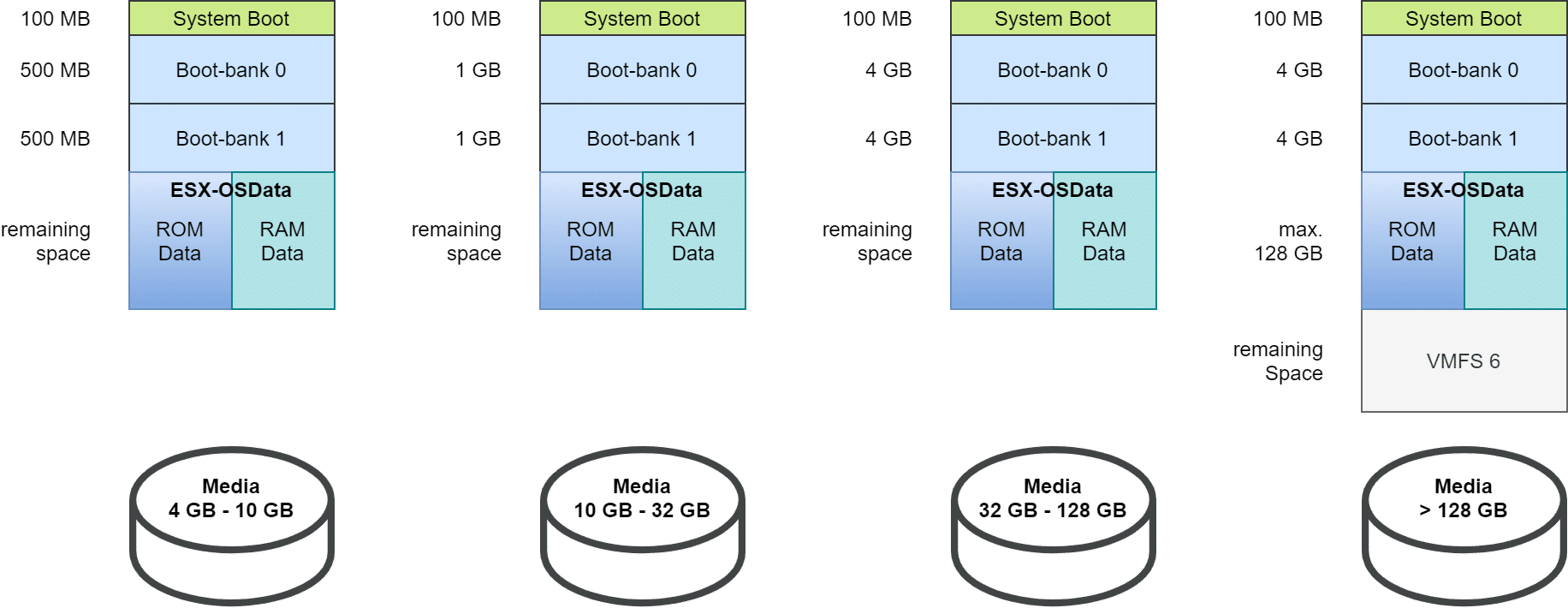
Zunächst wurde die Bootpartition von 4 MB auf 100 MB vergrößert. Auch die beiden Bootbänke wurden auf mindestens 500 MB angehoben. Die Größe gestaltet sich flexibel, abhängig von der Gesamtgröße des Mediums. Die beiden Diagnose-Partitionen (Small Core Dump und Large Core Dump), sowie Locker und Scratch wurden zusammengeführt in eine gemeinsame ESX-OSData Partition mit flexibler Größe zwischen 2,9 GB und 128 GB. Übriger Speicherplatz kann optional als VMFS-6 Datenspeicher bereitgestellt werden.
Unterschieden werden bei vSphere 7 vier Größenklassen für Bootmedien:
4 GB – 10 GB
10 GB – 32 GB
32 GB – 128 GB
> 128 GB
Dynamische Partitionierung unter vSphere 7 in Anhängigkeit von der Medienkapazität.
Die oben dargestellten Partitionsgrößen gelten für neu installierte Bootmedien unter ESXi 7.0. Doch wie sieht es für Bootmedien aus, die von Version 6.7 migriert wurden?