
Eine kleine Einführung in die Hochverfügbarkeit
Datenbestände an zwei Orten identisch zu halten, wird in der hochverfügbaren IT immer wichtiger. War dies noch vor einigen Jahren ein sehr teurer Luxus für das Enterprise Segment, so dringt diese Anforderung in den letzten Jahren immer weiter in den SMB Bereich vor. Diese Methode nennt man Spiegel und sie kann prinzipiell auf zwei Arten umgesetzt werden:
- asynchron – Der Datenabgleich erfolgt in definierten Intervallen. Dazwischen herrscht eine Differenz zwischen Quelle und Ziel.
- synchron – Der Abgleich erfolgt transaktionsgenau, sodaß der Datenbestand zu jedem Zeitpunkt auf beiden Seiten identisch ist. Ein Schreibvorgang gilt erst als abgeschlossen, wenn auch Spiegelziel den Schreibvorgang bestätigt hat.
Eine Voraussetzung für Hochverfügbarkeit ist die Spiegelung der Daten (synchron, oder asynchron). Sind die Daten an zwei Orten (Rechenzentren) vorhanden stellt sich eine weitere Designfrage: Soll das Speicherziel als Kopie für den Notfall fungieren (Active-Passive), oder soll an beiden Orten aktiv mit den Daten gearbeitet werden (Active-Active)?
- Active-Passive – In diesem Fall wird nur auf der aktiven Seite gearbeitet und die Daten auf die passive Seite übertragen (synchron oder asynchron). im Fehlerfall wird automatisch oder manuell (je nach Modell) umgeschaltet und die vorher passive Seite wird zur aktiven Seite. Sie bleibt dies, bis eine erneute Umkehr ausgelöst wird (Failback). Der Vorteil dieses Verfahrens ist, dass auch im Fehlerfall konstante Leistung garantiert werden kann. Die Ausstattung der passiven Seite muss natürlich identisch mit der aktiven sein. Der Nachteil besteht darin, dass nur maximal 50% der Ressourcen genutzt werden. Die anderen 50% stehen für den Fehlerfall bereit.
- Active-Active – Hier werden die Ressourcen beider Seiten parallel genutzt und die Hardware kann somit effizienter eingesetzt werden. Dies bedingt aber, dass im Fehlerfall die Hälfte der Ressourcen wegfällt und somit nicht die volle Leistung garantiert werden kann. Active-Active Designs erfordern einen Synchronspiegel, da beide Seiten mit identischen Daten arbeiten müssen.
Active-Active Cluster gibt es in vielfacher Ausprägung. Es gibt klassischen SAN-Storage mit integrierter Spiegelfunktion, oder Software-defined-Storage (sds) bei der die Spiegelung nicht in Hardware, sondern in der Software-Schicht erfolgt. Ein Beispiel dafür ist DataCore SANsymphony. Eine Sonderrolle nimmt hier der VMware vSAN Stretched Cluster ein, der aber nicht Gegenstand dieser Betrachtung sein wird.
Ich werde im folgenden Abschnitt auf eine Besonderheit von LUN basierten active-active Konstrukten eingehen, die leider oft übersehen wird, aber im Fehlerfall zu Datenverlust führen kann. VMware vSAN ist hiervon nicht betroffen, da dessen Stretched Cluster auf einem grundlegend anderen Verfahren beruht.
Betrachten wir zunächst einen Active-Active Cluster mit Synchronspiegel. Ob dieser nun in Hardware auf Controllerebene, oder in Software realisiert ist, spielt hier keine Rolle.
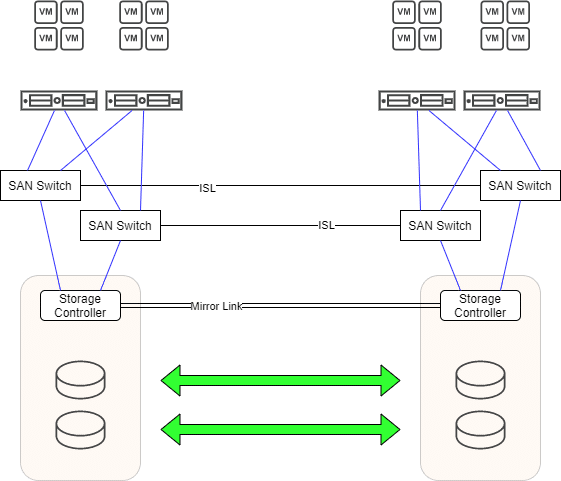
Die Situation
Wir sehen im Bild oben einen typischen Active-Active-Cluster. Ein redundanter Spiegelpfad sorgt für den Abgleich der gespiegelten LUNs auf beiden Einheiten. Es existieren zwei unabhängige Fibrechannel Fabrics mit jeweils einem SAN-Switch auf jeder Seite. Die Switches einer Fabric sind über einen Inter-Switch-Link ISL verbunden. Jeder Storage Controller ist redundant mit beiden Fabrics verbunden. Auf beiden Seiten gibt es ESXi Hosts die ebenfalls redundant mit beiden Fabrics verbunden sind. Jeder Host sieht jede LUN über 4 Pfade. Zwei (bevorzugte) lokale Pfade und zwei entfernte Pfade auf der gegenüberliegenden Seite. Im Fehlerfall findet ein transparenter Failover statt. Würde beispielsweise eines der beiden Storage Geräte ausfallen so laufen alle Arbeitslasten nahtlos auf der verbleibenden Storage weiter. Nach Behebung des Schadens werden die Änderungen über den Spiegelpfad synchronisiert. So weit, so gut.
Jede VM kann kann mit vMotion von Rechenzentrum 1 (RZ1) zu Rechenzentrum 2 (RZ2) migriert werden und bei Bedarf auch wieder zurück. Die Zuordnung der VMs auf LUNs kann automatisch (Storage-vMotion) oder manuell erfolgen. Wir haben also zwei wählbare Kriterien: Compute (ESXi) und Storage (LUN). Das schafft hohe Flexibilität. In vSphere eingebaute Automatismen sorgen für effiziente Lastverteilung.
Um das Szenario zu verdeutlichen, betrachten wir nur 2 VMs (Rot und Blau) , die auf der selben gespiegelten LUN liegen (vmdk Rot und vmdk Blau). VM Rot läuft in RZ1 und VM Blau in RZ2.
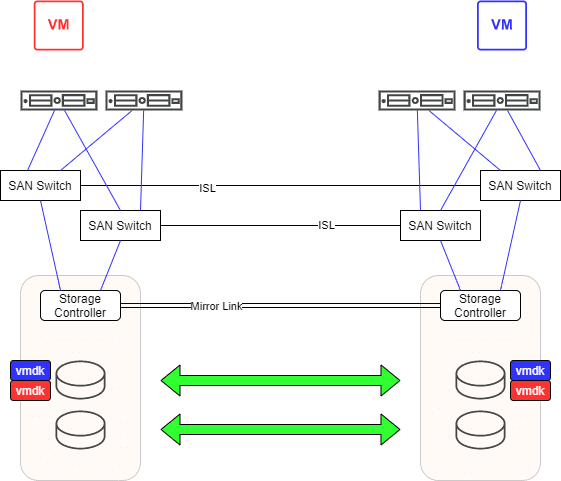
Wo ist das Problem?
Interessant wird dieses Design erst, wenn beide Rechenzenten voneinander isoliert werden. Das kann der berühmte Bagger sein, der versehentlich die Glasfasern zwischen den beiden Zentren kappt. Dazu gehört natürlich jede Art von LAN Kommunikation.
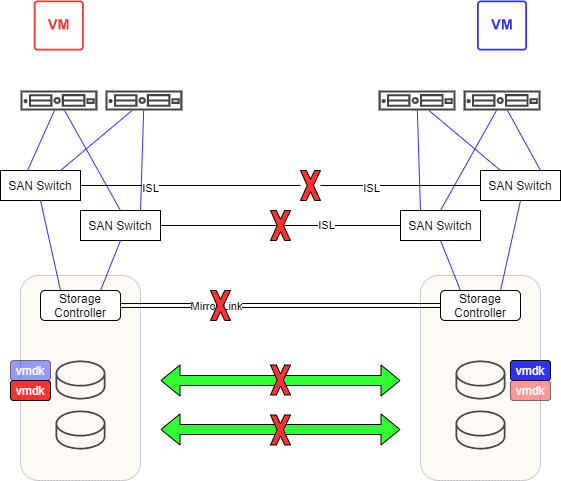
Was passiert mit unseren VMs? VM Rot verliert die Hälfte ihrer Pfade zur entfernten Storage in RZ2. Die lokale LUN in RZ1 ist aber weiterhin erreichbar. VM Rot läuft weiter. Für VM Blau sieht die Situation analog aus. Sie erreicht die LUN in RZ2 und verliert die Pfade zur LUN in RZ1. Auch VM Blau läuft weiter. Wir haben jetzt ein aktives VMDK File für Rot in RZ1 und eine verwaiste Kopie in RZ2 (hellrot). Für Blau ist es gerade umgekehrt. Ohne es zu merken, haben wir es mit zwei lebenden Zombies zu tun. Analog zu Schrödingers Katze ist die VM aktiv oder verloren. Das bemerkt man aber erst, wenn die Verbindungen zwischen den RZ wiederhergestellt werden.

Wir haben nun die Situation, dass sich Bild und Spiegelbild der LUN in unterschiedliche Richtungen entwickelt haben, die sich nicht mehr synchronisieren lassen. Es liegt ein Split-Brain Szenario vor. Der Administrator muss sich nun für eine der beiden Seiten entscheiden. Diese wird komplett neu auf die andere Seite gespiegelt. Alle dortigen Daten werden überschrieben. Entscheidet er sich für RZ1, so bleibt VM Rot in der aktuellsten Version erhalten, aber VM Blau fällt auf einen Stand unmittelbar vor der Verbindungstrennung zurück (hellblau). Der aktuelle Stand von VM Blau geht verloren. Entscheidet er sich für RZ2, so bleibt VM Blau aktuell, jedoch VM Rot fällt auf den alten Stand (hellrot) zurück. Eine klassische Pest oder Cholera Entscheidung.
Vorsorge
Das oben beschriebene Szenario wäre vermeidbar gewesen. Es erfordert nur ein wenig Planung und Steuerung. Der Aufwand ist überschaubar und alle notwendigen Mittel hierfür sind bereits in vSphere integriert.
Wenn wir gespiegelte LUNs eindeutig einem RZ zuordnen und auch die Hälfte der VMs einem RZ zuordnen, so wäre das oben beschriebene Szenario schmerzfrei aufzulösen.
Nehmen wir an, VM Rot gehört zur VM-Gruppe RZ1 und VM Blau zur VM-Gruppe RZ2. Wir erzeugen hierfür eine weiche DRS Regel. D.h. im Normalbetrieb sollte VM Rot in RZ1 und VM Blau in RZ2 laufen. Wenn wir jetzt noch dafür sorgen, dass alle VMs der Gruppe RZ1 auf einem Datenspeicher (oder Datenspeicher-Cluster) für RZ1 laufen und das gleiche mit den VMs der Gruppe RZ2 machen, dann erreichen wir eine saubere Trennung.
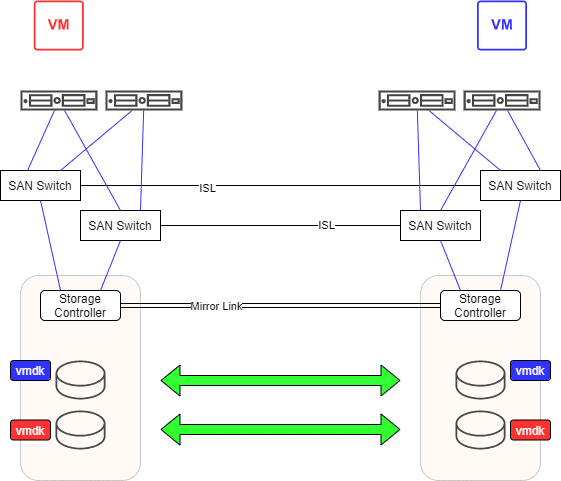
Alle VMs im RZ1 laufen auf zugewiesenen RZ1-Datenspeichern. Das gleiche gilt für VMs des RZ2, welche nur auf RZ2 Datenträgern laufen. Schlägt nun der Bagger zu, laufen wie zuvor die VMs beider Seiten weiter und auch die gespiegelten LUNs laufen wieder unvereinbar auseinander. Im Unterschied zum ersten Szenario haben wir jetzt aber die LUNs sortenrein (oder besser gesagt seitenrein). Auf einigen LUNs befinden sich ausschließlich VMs des RZ1, auf anderen ausschließlich VMs des RZ2.

Die Entscheidung, welche Seite nun zur aktiven deklariert werden soll ist einfach, denn sie findet auf LUN-Ebene statt. Es kann eine LUN von RZ1 nach RZ2 kopiert werden und eine andere wiederum von RZ2 nach RZ1. Überschrieben wird dabei jeweils nur die veraltete Kopie (hellblau, bzw. hellrot) der vmdk Dateien. Die aktuellste (blau und rot) bleibt erhalten.

Was passiert bei normalem Hardwareausfall?
Führt dieser Eingriff nicht zu geringerer Flexibilität, oder zu einer Verringerung der Hochverfügbarkeit? Ganz klar nein. Schauen wir uns die verschiedenen Ausfallszenarien einmal an.
Ausfall eines ESXi
Fällt in unserem Beispiel einer der beiden Hosts in RZ1 aus, so wird der verbleibende Host in RZ1 versuchen, alle VMs zu übernehmen. Reichen die Ressourcen des Hosts dafür nicht aus, so sorgt die weiche DRS Regel dafür, dass VMs temporär auch auf RZ2 betrieben werden können. Nach Beseitigung des Problems wird DRS die VMs wieder zurück migrieren.
Ausfall einer Storage Einheit
Bei Ausfall einer Storage Einheit werden alle VMs einen transparenten Pfad-Failover durchführen. Das ist problemlos möglich, da jede LUN über jede Storage erreichbar ist. Nach Beseitugung des Problems werden alle VMs wieder über die bevorzugten (lokalen) Pfade gegen die lokale Storage arbeiten.
Planung ist die halbe Miete
Im Vorfeld muss man sich natürlich ein paar Gedanken machen. Die Ressourcenanforderungen (Arbeitsspeicher, CPU) sollten einigermaßen gleichmäßig auf die beiden RZ verteilt sein. Auch die Belegung de Datenspeicher, oder genauer gesagt die Zugriffe darauf (i/o) sollten im Mittel gleichmäßig sein. VMs mit regem Datenaustausch sollten im selben RZ gruppiert werden. So bleiben die Wege der Datenpakete kurz. Wenn möglich, sollten für jede Seite mehrere LUNs zu Datenspeicher Clustern zusammengefaßt werden. Das gibt Storage-DRS Flexibilität bei der Lastverteilung.
Die Gesamtlast des Clusters sollte so bemessen werden, dass auch bei Ausfall eines ganzen Rechenzentrums noch genügend Ressourcen für den Betrieb aller VMs vorhanden sind. Dies lässt sich mit HA Zugangssteuerung (admission control) einrichten.
Wenn es sich zeigt, dass VMs die Seite wechseln sollten, dann muss unbedingt auch der Datenspeicher entsprechend gewechselt werden. Legt man hier keine Disziplin an den Tag, so ist nichts gewonnen und man endet im schlimmsten Fall in einer Situation, die ich eingangs beschrieben habe.
Tools
Es gibt eine Reihe nützlicher Hilfsmittel, die die Enscheidung erleichtern. VMware vRealize Operations kann tiefe Einblicke in den Ressourcenbedarf der eigenen VMs eröffnen und so helfen, die Aufteilung oder ggf. die Umverteilung zu planen. VMware vRealize Network Insight kann Fragestellungen zur Inter-VM Kommunikation beantworten.
Wer mit kleinerem Budget unterwegs ist, kann auf Software wie z.B. RVTools zurückgreifen. Dieses kostenlose Tools bietet schon sehr gute Übersicht aller VMs und deren Speicher, CPU- und RAM-Bedarf. Was fehlt ist die Betrachtung der Plattenzugriffe. Aber auch hier können mit esxtop und Perfmon die mit RVTools gesammelten Daten angereichert werden.