

Ich werde in Trainings und im Rahmen von vSAN Planungen immer wieder gefragt, warum über den eigentlichen Storage Bedarf hinaus noch einmal etwa 30% sogenannter Slackspace vorgehalten werden muss. Auf den ersten Blick sieht dies nach Verschwendung von teuren Ressourcen aus. Vor allem bei All-Flash Clustern ist das ein erheblicher Kostenfaktor. Oft wird dieser Slackspace als Reserve für zukünftiges Wachstum missverstanden. Dies ist jedoch keineswegs eine Reserve, die eingeplant werden darf. Vielmehr ist es ein Kontingent, welches für kurzzeitige Umlagerungen auf dem vSAN Datastore gebraucht wird.
Storage Policies
Ein großer Vorteil von vSAN im Vergleich zu herkömmlichen LUN basierten Datenspeichern, ist die flexible Änderung der Objektverfügbarkeit und Ausfallsicherheit. Musste man früher noch über die Auswahl des Datastores bestimmen, welche Verfügbarkeit oder Leistung eine VM, oder eine vDisk haben soll, so lässt sich dies bei vSAN über eine Storage-Policy regeln. Bei herkömmlicher Storage muss ich die Disk oder die ganze VM z.B. von einem RAID5 Volume auf ein RAID10 Volume verschieben. Bei vSAN genügt hierfür ein Mausklick im vCenter. Der VM, oder einem Teil der VM wird eine neue Policy zugeteilt und vSAN sorgt für die Einhaltung der darin definierten Ausfallsicherheit.
Dispo Speicher
Damit die Policy geändert werden kann, müssen temporär die Objekte (vDisks) sowohl in der alten Konfiguration, als auch in der zukünftigen Konfiguration nebeneinander existieren bis der Wandlungsvorgang abgeschlossen ist. Erst dann können die alten Objekte entfernt werden. Für die Übergangsphase wird zusätzlicher Datenspeicher benötigt.
Im Beispiel unten ändert sich die Storage Policy einer 120 GB Disk von Mirroring (RAID1) mit einfacher Ausfallsicherheit (Failures to Tolerate, FTT) auf Erasure Coding (EC). Erasure Coding ist kein RAID5, auch wenn es leider oft so bezeichnet wird, denn der Algorithmus zur Paritätsberechnung ist komplett verschieden.
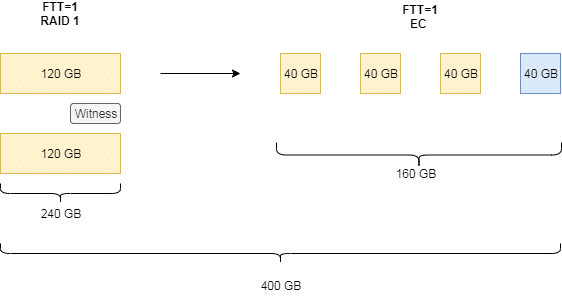
Im oben dargestellten Fall haben wir ursprünglich eine Mirror-Policy (FTT=1). Hier wird das Objekt gespiegelt und auf zwei unterschiedlichen Hosts abgelegt. Für 120 GB Nettodaten werden insgesamt 240 GB im Datenspeicher belegt. Als Schiedsrichter im Falle einer Hostisolation fungiert eine kleine Witness Komponente auf einem dritten Host, die jedoch nur wenich Speicherplatz benötigt und daher hier vernachlässigt wird.
Für die Umstellung der Policy auf Erasure Coding wird die Datendisk auf drei Datenkomponenten aufgeteilt und durch eine vierte Paritätskomponente ergänzt. Erasure Coding erfordert 2n+2 Hosts, wobei n die gewünschte Anzahl der möglichen Hostfehler ist. Im Beispiel oben ist n=FTT=1 und somit werden werden vier Hosts benötigt.
Bis zum Abschluss des Vorgangs liegen alle Objekte der alten und neuen Policy nebeneinander vor und belegen Speicherplatz. Aus Ursprünglich 240 GB (120 GB gespiegelt) werden zwischenzeitlich 400 GB.
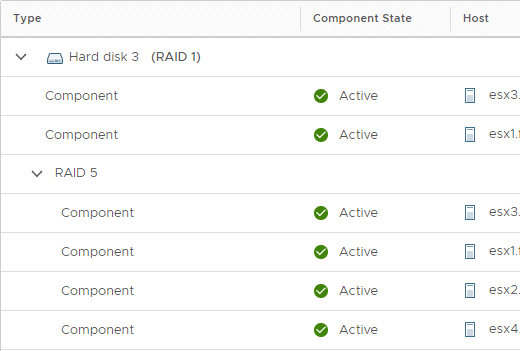
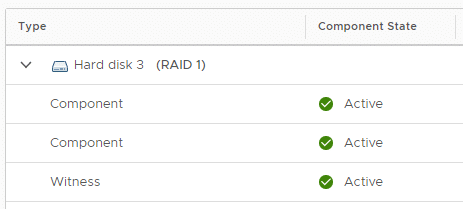
Man kann im vCenter diesen Vorgang gut beobachten. Im Bild oben sind die beiden ursprünglichen Mirror Komponenten zu sehen, die auf ESX1 und ESX3 liegen. Zusätzlich werden vier neue EC Komponenten aufgebaut, die auf ESX1, 2, 3 und 4 verteilt sind.
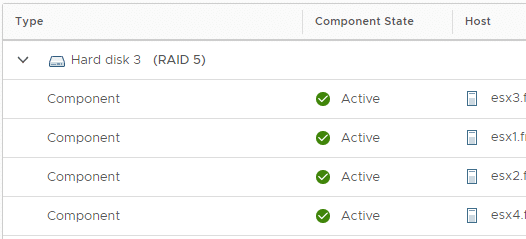
Nach Abschluss der Transformation werden die beiden Spiegelobjekte und der Witness gelöscht und es bleiben vier Komponenten a 40 GB zurück.
Beispiel mit FFT=2
Beim Wechsel der Policies mit höherer Ausfallsicherheit (z.B. FTT=2) sieht das Phänomen ähnlich aus.
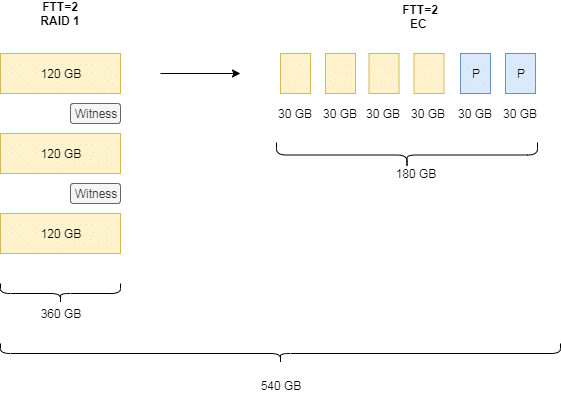
Im Beispiel oben war ursprünglich eine Spiegel Policy mit FTT=2 vorgegeben. D.h. das Diskobjekt muss auf drei verschiedenen Hosts gespiegelt werden. Hinzu kommen zwei kleine Witness Objekte auf zwei weiteren Hosts. Die Policy wird umgestellt auf Erasure Coding mit FTT=2. Wegen der Anforderung 2n+2 benötigen wir jetzt vier Datenkomponenten und zwei Paritätskomponenten, die auf sechs hosts verteilt werden müssen. Der Speicherbedarf steigt hierfür zwischenzeitlich von 360 GB (3x 120GB) auf 540 GB an um dann nach Abschluss auf 180 GB zu sinken.
Fazit
Ich hoffe die Darstellung war anschaulich genug, um zu erkennen wofür der Slackspace im vSAN Cluster gebraucht wird. Auch bei vollständiger Ausschöpfung des eigenen Bedarfs, ist immer noch etwas Spielraum für Policy Änderungen notwendig.