
Für jemanden, der hauptsächlich im FibreChannel Protokoll zu Hause ist, dem bereitet iSCSI immer wieder Spaß und Kurzweil. So geschehen in der vergangenen Woche, als wir ein verzwicktes Phänomen bei der Einbindung eines iSCSI Targets hatten. Auch wenn es eine gute Fingerübung für Troubleshooting war, so brachte es einige graue Zellen zum Rauchen.
Das Szenario
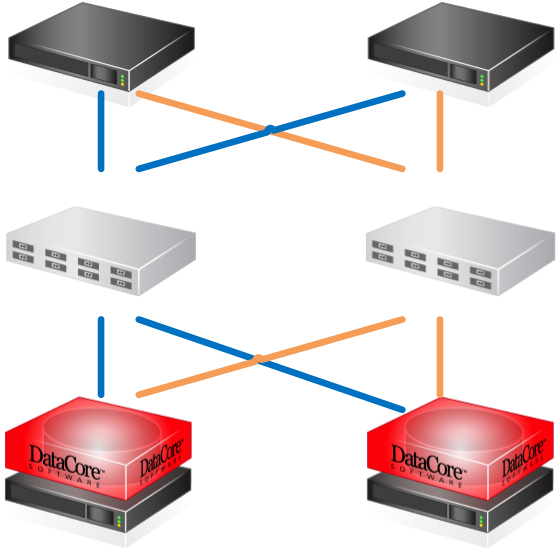
- Zwei ESXi 5.5 Server mit je 2x1Gbit LAN Adapter für iSCSI
- je 2 Kernelports in unterschiedlichen Subnetzen (10.0.0.x und 10.0.1.x) unabhängig von Management Network und VM-Network (192.168.1.x)
- keine Jumboframes (MTU 1500)
- zwei LAN Switches für Redundanz
- 2 Datacore Server mit SANsymphony-V 10 und je 2 x 1Gbit für iSCSI Frontend Ports [FE]
| Host | iSCSI1 | iSCSI2 |
|---|---|---|
| ESX4 | 10.0.0.14 (vmk4) | 10.0.1.14 (vmk5) |
| ESX5 | 10.0.0.15 (vmk4) | 10.0.1.15 (vmk5) |
| SDS1 | 10.0.0.31 | 10.0.1.31 |
| SDS2 | 10.0.0.32 | 10.0.1.32 |
Das Phänomen
Bei der Konfiguration des Software iSCSI Adapters kam jeweils nur für einen Kernelport eine iSCSI Verbindung zustande. Das Verhalten war auf beiden ESXi Servern gleich.
Test der Kernelports
Zunächst sollte der physische Kontakt von Kernelport zu Targetport getestet werden. Das Kommando hierfür ist vmkping.
~ # vmkping -I vmk4 10.0.0.31 PING 10.0.0.31 (10.0.0.31): 56 data bytes 64 bytes from 10.0.0.31: icmp_seq=0 ttl=128 time=0.449 ms 64 bytes from 10.0.0.31: icmp_seq=1 ttl=128 time=0.155 ms 64 bytes from 10.0.0.31: icmp_seq=2 ttl=128 time=0.152 ms --- 10.0.0.31 ping statistics --- 3 packets transmitted, 3 packets received, 0% packet loss round-trip min/avg/max = 0.152/0.252/0.449 ms ~ # vmkping -I vmk5 10.0.1.31 PING 10.0.1.31 (10.0.1.31): 56 data bytes 64 bytes from 10.0.1.31: icmp_seq=0 ttl=128 time=0.300 ms 64 bytes from 10.0.1.31: icmp_seq=1 ttl=128 time=0.137 ms 64 bytes from 10.0.1.31: icmp_seq=2 ttl=128 time=0.147 ms --- 10.0.1.31 ping statistics --- 3 packets transmitted, 3 packets received, 0% packet loss round-trip min/avg/max = 0.137/0.195/0.300 ms
Es besteht also Kontakt zu beiden Ports des Targetservers (auch zu den beiden Ports des zweiten DataCore Servers, jedoch hier nicht dargestellt). Sendet man jedoch ein PING ohne Angabe des Kernelports, so sieht das Ergebnis anders aus.
~ # ping 10.0.0.31 PING 10.0.0.31 (10.0.0.31): 56 data bytes --- 10.0.0.31 ping statistics --- 3 packets transmitted, 0 packets received, 100% packet loss ~ # ping 10.0.1.31 PING 10.0.1.31 (10.0.1.31): 56 data bytes 64 bytes from 10.0.1.31: icmp_seq=0 ttl=128 time=0.124 ms 64 bytes from 10.0.1.31: icmp_seq=1 ttl=128 time=0.168 ms 64 bytes from 10.0.1.31: icmp_seq=2 ttl=128 time=0.139 ms --- 10.0.1.31 ping statistics --- 3 packets transmitted, 3 packets received, 0% packet loss round-trip min/avg/max = 0.124/0.144/0.168 ms
Das gleiche Verhalten auf dem zweiten ESX Server und dem 2. Datacore Server.
Was war passiert?
Es fällt auf, dass immer bei normalen Pings in das 10.0.0.x Netz es zu Paketverlusten kommt. Sendet man jedoch gerichtete PINGs unter Angabe des Kernelports, ist alles in Ordnung. Ein wenig Recherche im Netzwerk der ESX Server brachte die Lösung. Es existierte bereits ein Subnetz 10.0.0.x für vMotion mit eigenen Kernelports (vmk2, vmk3). Ein ungerichteter Ping nimmt immer den Kernelport mit der niedrigsten Nummer. Das war in diesem Fall vmk2. Dieser führt aber zu keinem iSCSI Target. Eine Verschiebung der IP Subnetze beseitigte das Problem.
Neue Konfiguration
| Host | iSCSI1 | iSCSI2 |
|---|---|---|
| ESX4 | 10.0.1.14 (vmk4) | 10.0.2.14 (vmk5) |
| ESX5 | 10.0.1.15 (vmk4) | 10.0.2.15 (vmk5) |
| SDS1 | 10.0.1.31 | 10.0.2.31 |
| SDS2 | 10.0.1.32 | 10.0.2.32 |
Beide iSCSI Targets antworten nun problemlos auf PING Anfragen.