
Kurz nach dem Erscheinungdatum berichtete ich im Artikel Datacore SANsymphony-V 10 Release über die neuen Features von Datacore SANsymphony-V Version 10. Dabei handelte es sich jedoch nur um die Wiedergabe der Release-Notes. Ich möchte nun näher auf die neuen Funktionen eingehen und diese etwas näher beleuchten.
- Virtual SAN
- Smart Deployment
- Auto Optimierung
- Leistungsanalyse
- High Performance Networking
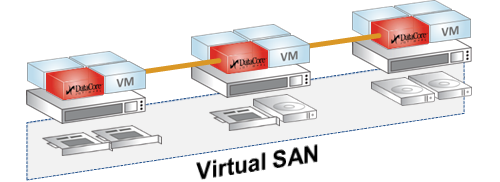
Virtual SAN
DataCore Virtual SAN (vSAN) kombiniert Hochverfügbarkeit und Höchstleistung. Durch Direct-Attached-Storage (DAS) wie zum Beispiel Flash, PCIe, SSD, SAS-HDD entfallen viele Flaschenhälse. Virtual SAN poolt diese DAS Ressourcen und stellt sie bereit. Redundanz und Hochverfügbarkeit wird durch ein Grid mit 2 bis 32 Knoten (N+1) ermöglicht.
Skalierbarkeit
Das Konzept erlaubt ein Scale-up bis zu 32 Petabyte und ein Scale-out bis zu 32 Knoten. Datacore läuft in diesem Modell als VM auf einem Hypervisor (z.B. VMware oder Hyper-V), der auf Servern mit lokalem Storage läuft.
Virtual-SAN lässt sich mit physischer SAN kombinieren. Das ist sicherlich ein wichtiger Vorteil zu anderen vSAN Lösungen, die in sich isoliert sind.
Smart Deployment Wizard
Zur Vereinfachung des Setup wurde der Smart Deployment Wizard entwickelt. Natürlich kann man aber weiterhin Datacore Cluster mit der herkömmlichen Methode ausrollen. Der Wizard ist aber ein gutes Hilfmittel zur Vereinfachung der Erstinstallation oder zur Erweiterung.
Der Smart Deployment Wizard verbirgt sich unter dem namen SDW zwischen den Setup Dateien. Dies ist ein selbst-extrahierendes Archiv, welches zunächst nach einem temporären Speicherplatz für die entpackten Dateien fragt.
 Dort findet man den eigentlichen Wizard.
Dort findet man den eigentlichen Wizard.

Templates
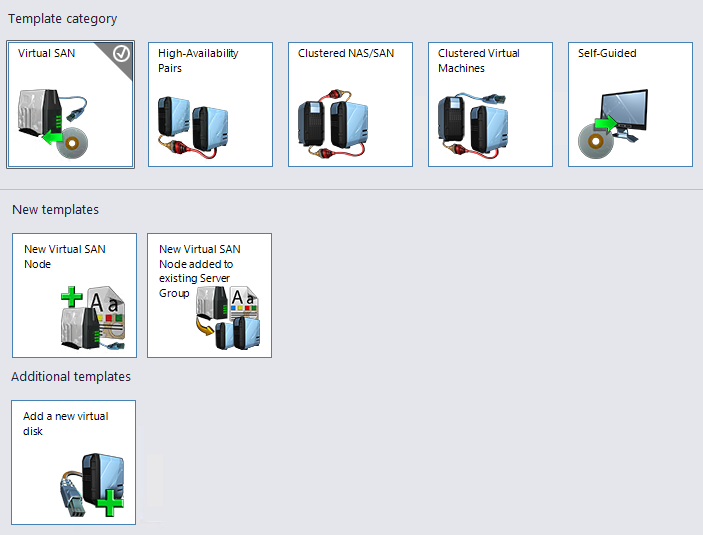
Für die unterschiedlichen Bereitstellungs-Szenarien bietet die Assistenten-gesteuerte Installation eine Auswahl an Installationsvorlagen (Templates).
- Virtual SAN
- HA Pairs
- Clustered SAN/NAS
- Clustered VMs
- Self Guided
Ich habe den Wizard auf einem bestehenden Datacore Server erneut gestartet. Daher der Hinweis, daß bereits eine Konfiguration für ein HA-Pair vorhanden ist.
 Jede dieser Kategorien hat 1-2 zugehörige Templates zur Neuanlage, oder zur Erweiterung.
Jede dieser Kategorien hat 1-2 zugehörige Templates zur Neuanlage, oder zur Erweiterung.
Automatisierte Optimierung
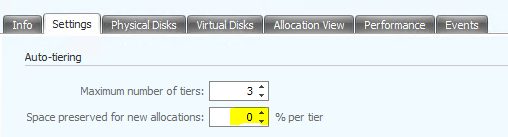
Preemptives Tier Space Management
Hier wird ein wählbarer Prozentsatz des Tier Speichers reserviert für die Bereitstellung und Verschiebung. Dieser prozentuale Bereich gilt für alle Tiers mit Ausnahme des niedrigsten. Somit können SAU (Storage Allocation Units) schneller nach oben oder unten wandern wenn im Ziel-Tier bereits freier Bereich vorhanden ist. Neue Bereistellungen gehen sogar komplett in den bestmöglichen Tier Level und werden erst später entsprechend ihren Anforderungen verschoben. Damit ist die Bereitstellung neuer VMs beschleunigt und diese müssen sich nicht erst durch mehrere Tier-Ebenen hocharbeiten.
Die Einstellung erfolgt auf Ebene des Disk-Pools.
Write-aware Auto-Tiering
Bis Version 9 wurden lediglich Lese-IO herangezogen, um den Tier Level der SAU festzulegen. Das ändert sich nun mit Version 10, indem (wahlweise) auch Schreib-IO berücksichtigt werden. Dazu muss ein neues Speicher-Profil erstellt werden. Die voreingestelleten Profile basieren nur auf Lese-IO. Die Funktion wird von Datacore dezeit noch als „experimentell“ eingestuft.
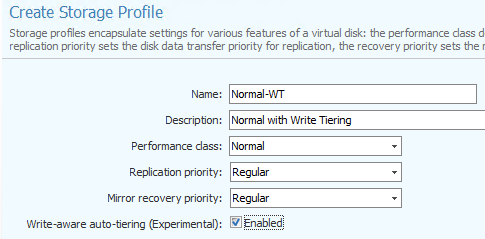
Intelligente Lastverteilung
Verbesserte Lastverteilungs-Logik beachtet vDisks, wenn SAUs über physische Festplatten verteilt werden. Somit wird vermieden, dass SAUs, welche zur gleichen vDisk gehören, sich auf wenigen physische Spindeln konzentrieren.
Gezielte Wiederherstellung
Beim Ausfall einer Disk im Diskpool musste bisher ein Full Recovery des gesamten Pools vom verbleibenden Datacore Host auf den Host mit der beschädigten Disk gefahren werden. Mit unter konnte dies eine gewaltige Datenmenge sein, die über den Spiegel geschickt werden musste. Dies ist ab Version 10 verbessert. Ein Purge-Assistent ermittelt, welche Disk betroffen ist, und welche SAUs sich darauf befanden. Die gepiegelte vDisk wird wiederhergestellt, indem nur die fehlenden SAUs von der gesunden Seite übertragen werden. Ein erheblicher Zeitvorteil!
Verbesserte Darstellung von Leistungsdaten
Darstellung der Heatmap
Die SAUs werden sortiert nach „Hitze“ dargestellt. Somit wird die Auslastung der Disks innerhalb eines Tiers übersichtlicher. Zum Vergleich sind hier die Allocation Views von SSY9 und SSY10 gegenübergestellt.
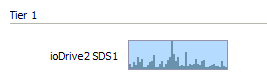
Allocation View in SSY9
In diesem Beispiel bildet ein io-Drive2 von Fusion-IO den Top-Tier. Es ist voll belegt und enthält die heissesten Blöcke des Systems. Die Verteilung zwischen ganz heiss und weniger heiss muss man aber anhand der Peaks schätzen.
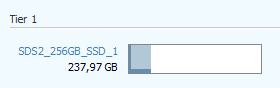
Allocation View in SSY10
Zugegeben, dieser Speicher hat derzeit noch nicht wirklich viel zu tun, aber man kann erkennen dass die heissen Blöcke (SAU) links sortiert sind.
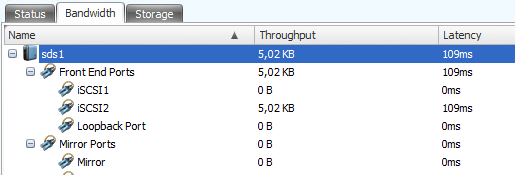
System Health – Bandbreite
System Health zeigt schön übersichtlich die Leistungsdaten in Bezug auf Latenz und Durchsatz für alle Ports.
Darstellung neben der Heatmap
Latenzen und IOPS werden auch neben der Heatmap angezeigt.

IO Poller Prozess-Verbesserungen
Das Thread Scheduling auf Multi-Core CPU wurde optimiert. Die IO-Poller Instanzen skalieren nun dynamisch. Es werden immer mindestens zwei Thread Instanzen verwendet (außer die CPU Anzahl im server ist <=4). Wenn die Frontend Last ansteigt und mehrere CPU verfügbar sind, werden weitere Threads gestartet.
In der Leistungsanzeige kann man neue Counter überwachen
- ProductivePolls
- UnproductivePolls
- TotalThreads
Netzwerk Verbesserungen
Es gibt mehr Auswahlmöglichkeiten für Hochleistungsadapter.
iSCSI and Remote Replication
- 10/40 GbE Emulex NIC
- 10/40/56 GbE Mellanox NIC
- 40/56 GbE Mellanox Switch
NIC Teaming
NICs können zu Teams zusammengefasst werden. Dabei kann entweder die Bandbreite erhöht, oder die Redundanz verbessert werden. D.h. der Link bleibt aktiv, auch wenn ein NIC down ist.
Links
- Datacore – Virtual SAN Features